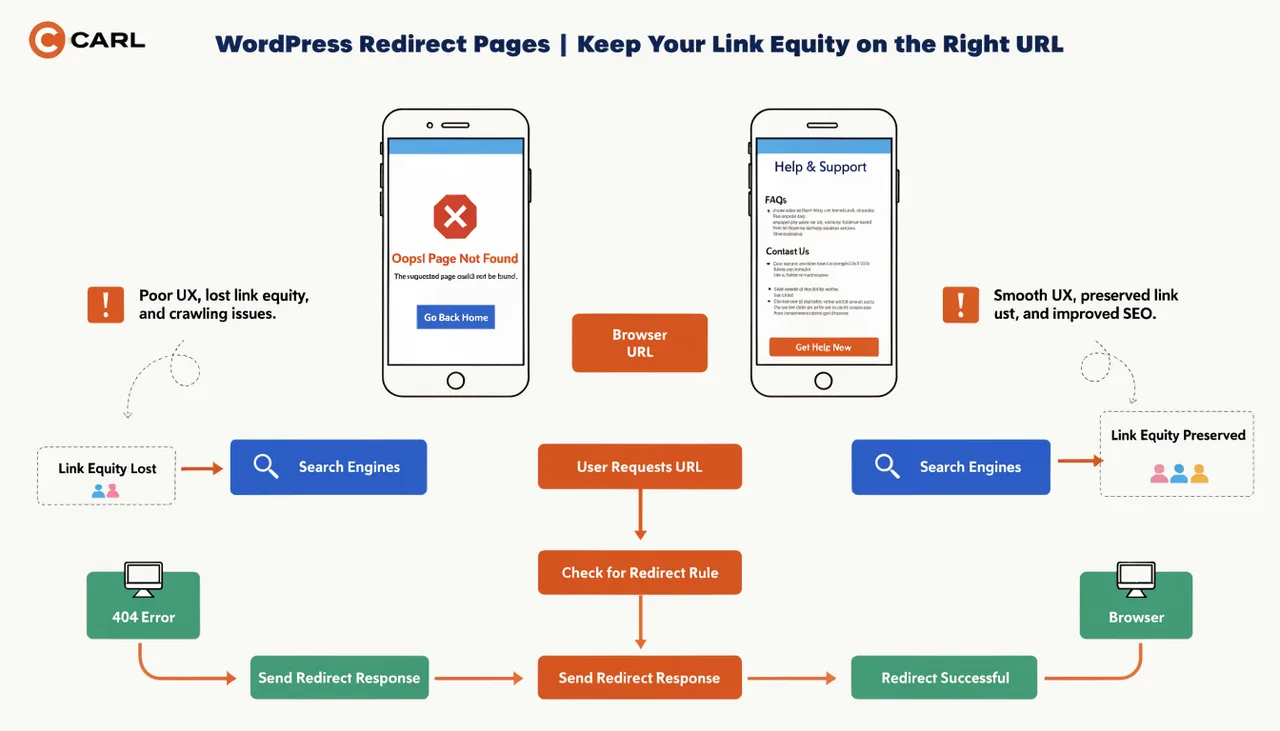
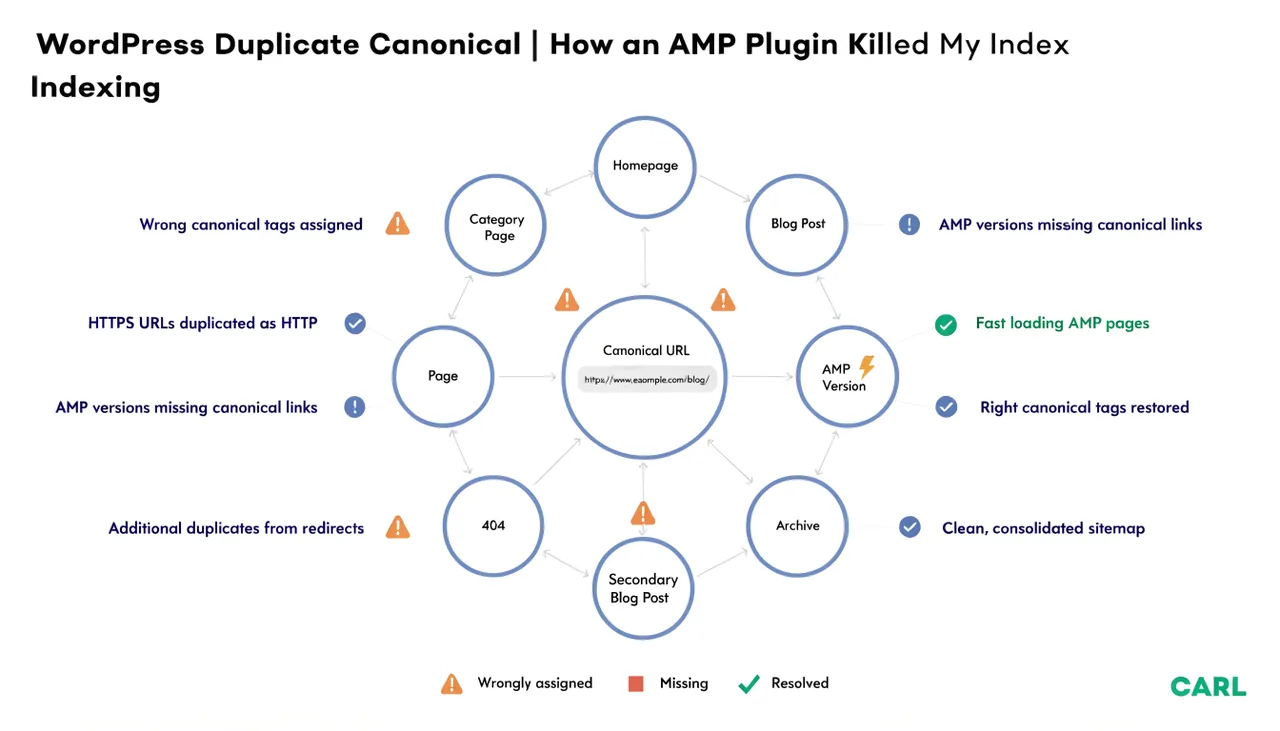
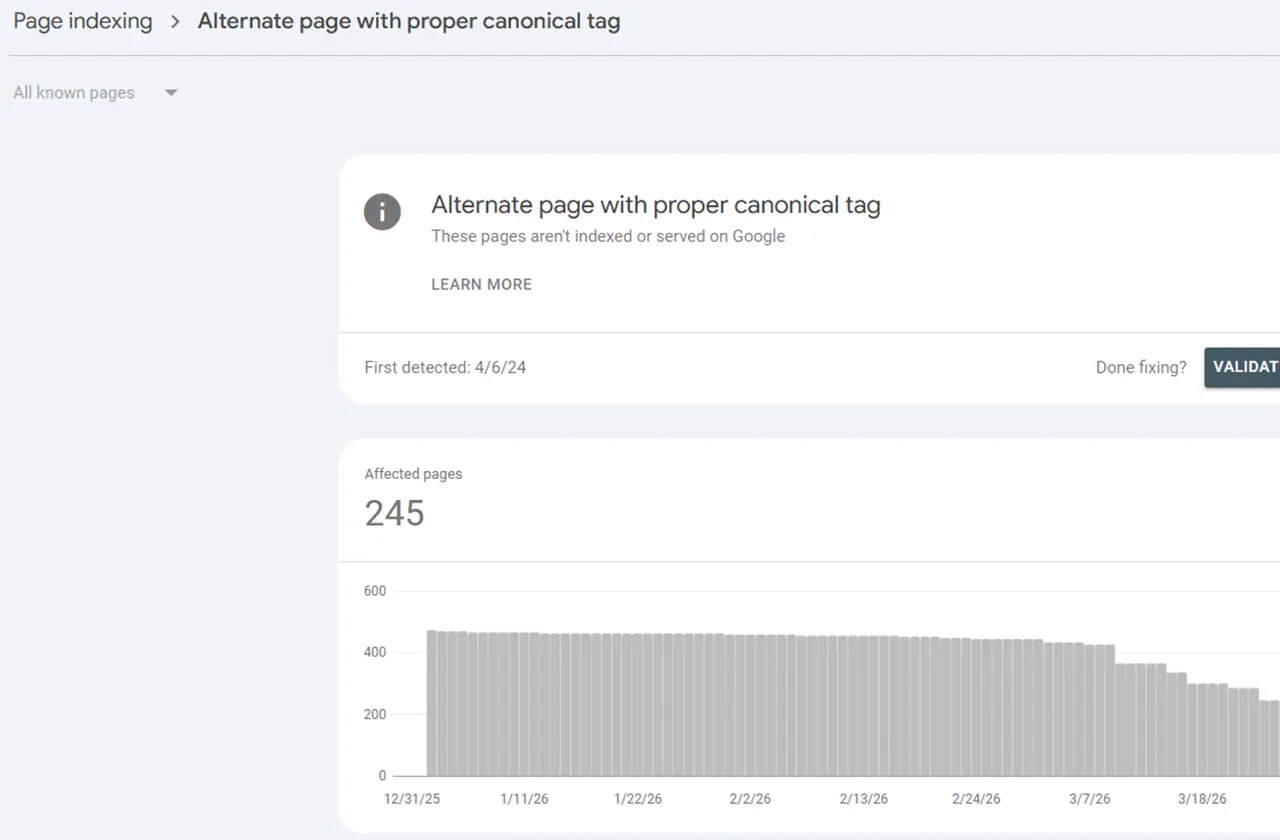
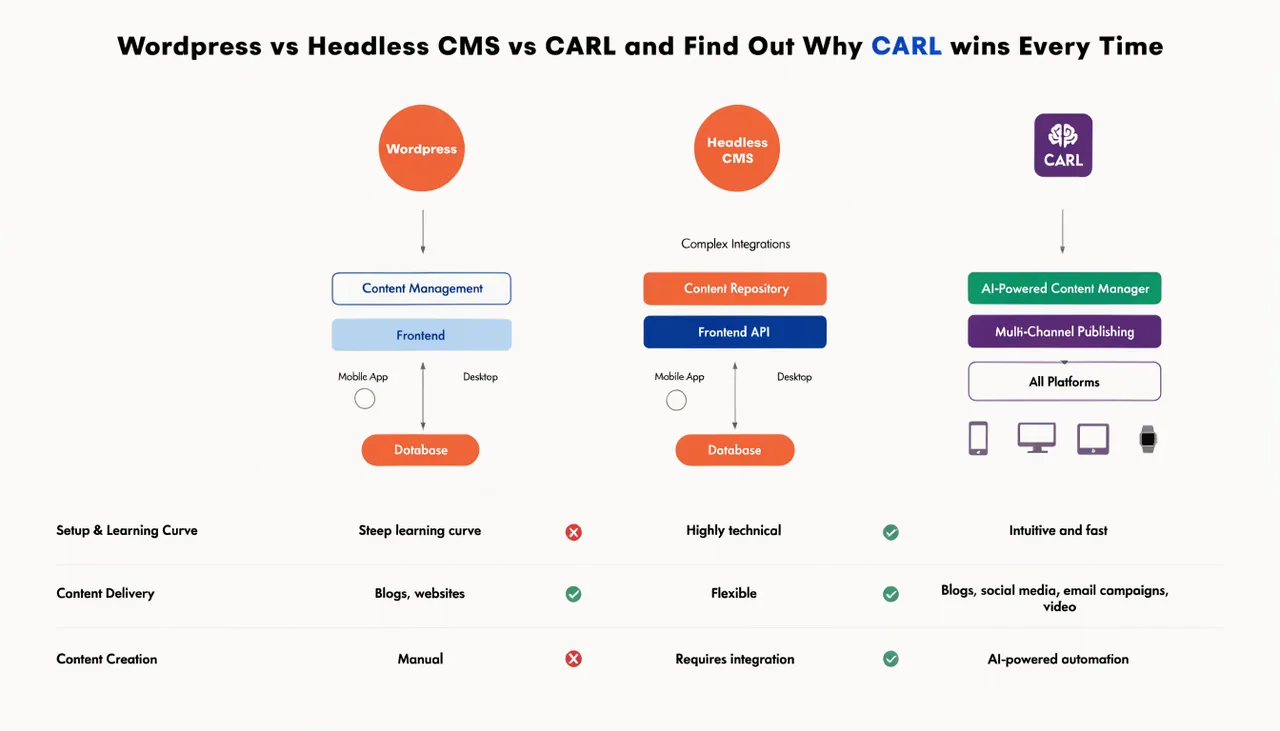
WordPress 4xx Errors - Google Is Crawling Pages You Never Built
By Carl Riedel, Builder of CARL, Recovering WordPress Survivor
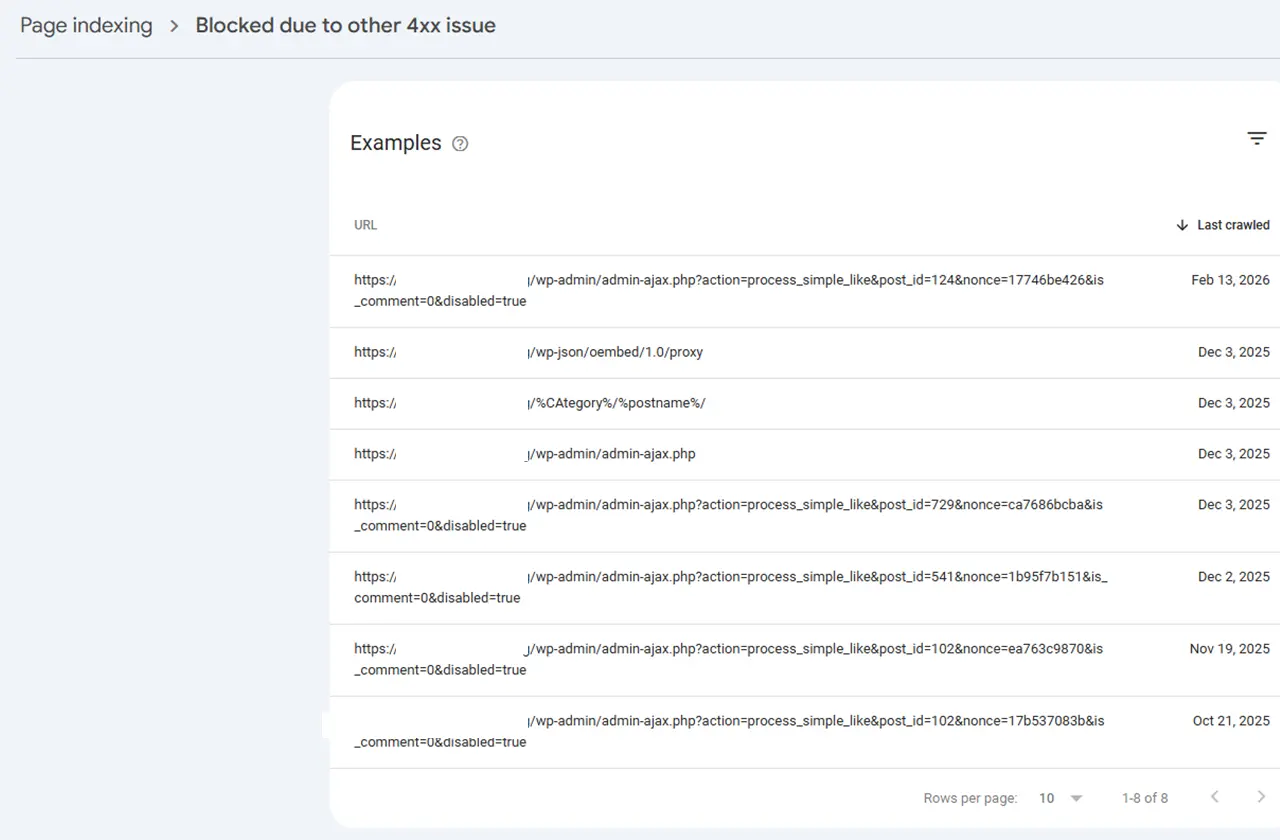
Open Google Search Console on a WordPress site and go to Page Indexing. Find the "Blocked due to other 4xx issue" report. Click into it and look at the examples.
What you'll see are URLs like these:
/wp-admin/admin-ajax.php?action=process_simple_like&post_id=124&nonce=.../wp-json/oembed/1.0/proxy/%CAtegory%/%postname%//wp-admin/admin-ajax.php
You didn't create any of those. WordPress did. And Google has been crawling them, hitting 4xx errors, and logging every one of them as a blocked page on your site.
Pages You Never Built
This is the part that surprises most WordPress site owners. They assume Google only crawls the pages they actually created: articles, category pages, the homepage. The reality is that WordPress exposes a substantial number of additional URLs to the public internet without telling you.
The REST API ships enabled by default. Every WordPress installation has a publicly accessible JSON endpoint at /wp-json/ exposing your content, your users, and your site structure in machine-readable format. Googlebot follows it.
The AJAX handler at /wp-admin/admin-ajax.php processes plugin requests. Plugins use it for likes, shares, dynamic content loading, and dozens of other functions. Every one of those requests generates a URL with query parameters that Googlebot can follow and index, or try to, and fail.
The oEmbed proxy at /wp-json/oembed/1.0/proxy handles media embeds. The malformed category URL /%CAtegory%/%postname%/ is an unfilled permalink template that somehow made it into the crawl. These aren't edge cases. They're standard WordPress behaviour that millions of sites are dealing with right now.
What This Costs You
Googlebot operates on a crawl budget. For most sites it's not unlimited. Google allocates a certain amount of crawl capacity based on your site's authority, speed, and server health. Every request Googlebot makes to your site uses a slice of that budget.
When Google is burning crawl requests on /wp-admin/admin-ajax.php?action=process_simple_like&post_id=541&nonce=1b95f7b151 it is not using that same request to crawl and index your actual content. Your real articles, your product pages, your carefully written guides — they're competing for crawl attention with URLs that should never have been publicly accessible in the first place.
On a young site trying to establish authority, wasted crawl budget is a real cost. Pages that should be indexed within days sit in the crawl queue for weeks because Googlebot is busy hitting dead ends your platform created without asking.
The Standard Advice and Why It's a Treadmill
The standard fix is to add rules to robots.txt blocking /wp-admin/ and /wp-json/, configure your SEO plugin to disable the REST API for public access, and audit your plugins to find which ones are generating the AJAX URLs showing up in GSC.
That advice is not wrong. But you're mopping the floor with the tap open and overflowing again. WordPress will keep generating new publicly accessible endpoints as you install plugins. Every new plugin is a potential source of fresh AJAX URLs, new REST API routes, new endpoints Googlebot will find and follow. You patch one batch, install a new plugin, and 6 months later you're back in GSC looking at a fresh set of blocked URLs.
My GSC report showed 8 examples across multiple dates, some going back to late 2025. First detected, still appearing months later. The platform keeps creating the problem faster than manual fixes can contain it.
What CARL Generates Instead
CARL generates exactly the pages you create. Nothing else.
There is no REST API. There is no /wp-json/ endpoint. There is no admin-ajax.php handler. There are no oEmbed proxies. There are no unfilled permalink templates floating around in Googlebot's crawl queue.
When you generate a page in CARL, a single PHP file is written to your server at the exact path you specified. That's the only URL that exists. Google crawls it, indexes it, and moves on. There are no surprise URLs hiding behind your content, no plugin-generated endpoints polluting your crawl data, no admin handlers publicly accessible by design.
Your crawl budget goes entirely to your actual content. Every URL Google finds on a CARL site is a page you deliberately created and want indexed. That's not a configuration you achieve by blocking things in robots.txt. It's the natural result of a platform that only generates what you ask it to.
Ready to build a site that can't be taken down by a student's plugin?